二:HelloWorld
采用QEMU制作的最小linux顺利启动后,就该为其写内核模块了,所以这一节就是热热身:
- 学习如何通过vscode搭建linux驱动开发环境
- 编写第一个内核模块helloworld
- 初识linux内核模块机制
警告:在开始阅读下文之前,务必确保自己的linux内核被交叉编译过,并顺利生成zImage。
Ubuntu+VSCode的驱动开发环境搭建
2015年底微软用自己的行动向世人证明,在IDE领域,你大爷还是你大爷,即便是Visual Studio Code这种所谓的代码编辑器,都可以傲视一堆所谓功能强大的集成开发环境。随着近几年的更新迭代,vscode在c/c++的开发方面也不逊色于vs了(我个人感受),在GO、Web、C/C++以及很多非主力语言,它都是我的首选。因此,之后的内核模块代码编写,自然也少不了这利器。(一不小心闲话扯多了)
进入正题,vscode安装好之后,务必安装微软官方扩展——C/C++,这个扩展的好处是提供语法高亮、智能补全、提示、调试等核心功能,剩下的酷炫功能及教程自行看官网。对于驱动来说,主要是方便代码补全和接口提示,以提高编写效率。
vscode及其扩展安装完毕后,开始写代码吧,创建第一个驱动源码——hello.c
1 | $ mkdir ~/varm/drivers/hello |
先别急着写代码,vscode扩展需要我们告诉它从哪里解析头文件,以分析和自动补全你想要的接口形式,所以:
1 | ~/varm/drivers/hello$ mkdir .vscode # 创建vscode当前项目配置目录 |
打开刚创建的json配置文件,并把下方的内容拷贝进取,不过要注意includePath部分,里边的路径是我自己的环境,说白了就是要告诉vscode从哪里能够找到linux内核以及arm架构所需的头文件位置,这个需要根据自己的实际情况作调整。
1 | { |
好了,现在可以愉快地写代码了,就像下图这样,vscode驱动开发环境配置结束。
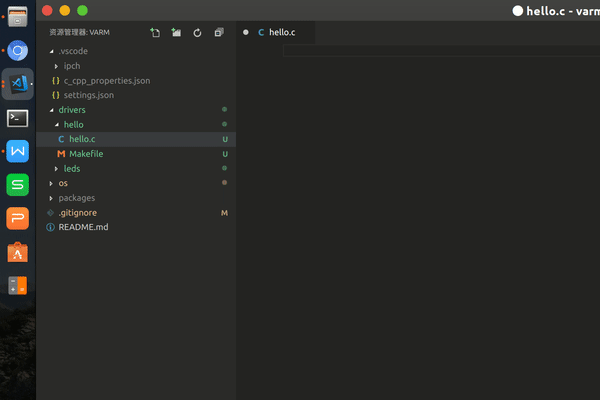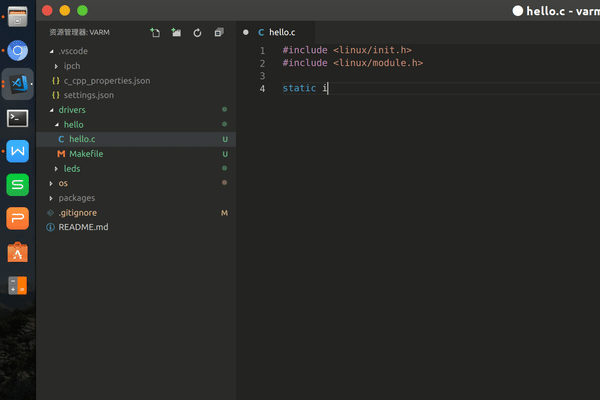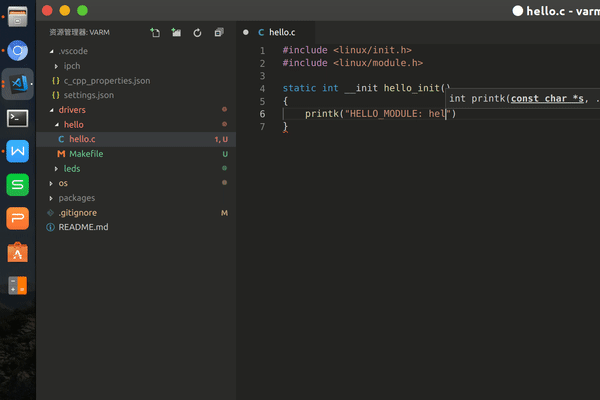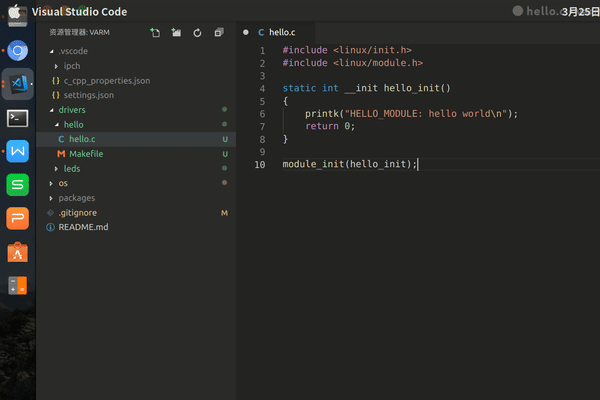
第一个linux内核驱动
先看代码!
1 |
|
上述代码可以说非常简单了,我们定义了两个函数hello_init/hello_exit都只是简单打印了一句话,并通过module_init/module_exit分别告诉内核,当加载/卸载该模块的时候执行对应的函数。
为什么不用printf函数打印
一是因为printf是C的标准库函数,依赖于C的动态库文件,比如/lib/libc.so.6文件,内核就不应该直接去访问这个文件。
二是因为模块是运行在内核层,而非用户层,printf要通过用户文件系统把内容输出到文件,同样是第一条理由,所以printk也就是指通过内核输出。
不光printk,内核开发中还会遇到很多k结尾的函数,比如mallock,都是因为标准C库的原因,不能直接调用,但其功能及接口形式与标准库几乎一样。
两个函数前__init/__exit意味着什么
这两个是修师符,即使不添加也不会有任何表面上的区别,但建议加上!
__init表示该函数是初始化函数,在最终生成的模块文件中,这段代码会被强制放到.init.text段区,当模块加载完毕后,该区所有分配的内存资源都会被释放。__exit表示该函数是退出函数,如果你的驱动并非“模块”,而是直接编译进内核,那么被此修饰的函数显然是多余的(编译到内核中的驱动是无法卸载的),因此该函数不会被链接,以缩小镜像大小。
关于开源与许可证
这部分会涉及到非常多的法律问题和风险,一般来说如果一个驱动没有声明GPL协议,在加载时会收到内核被污染的警告,逼死强迫症。但是对于我等初学小白而言,可以暂时不用考虑这部分内容。但如果是工作中的代码或涉及商业机密,建议还是谨慎对待,毕竟不是每个程序员都善于打官司。
编译并“运行”驱动
第一步:编译
linux的内核模块编译是必须依赖内核源码的,这就是为什么文章一开始注明必须确保linux内核已经交叉编译过的原因。而内核模块需要通过Makefile来指定是编译到内核中,还是以模块形式存在,也就是下面的第一行obj-m=hello.o。
1 | # 模块驱动,必须以obj-m=xxx形式编写 |
除了第一行需要留意下以外,其他都是常规Makefile语法,本文主要关注驱动开发,其他语法规则什么的就不废话了。直接make一下就能看到hello.ko的出现,这就是最终内核模块。
第二步:拷入根文件系统
虽然linux内核模块是运行在内核层的,但其加载、卸载、访问、操作等策略性的事物是完全交由用户层来管理,驱动仅仅负责实现和提供设备访问机制。所以现在需要把编译好的ko文件拷贝到之前制作好的根文件系统镜像中——rootfs.ext3。
目前我们的linux最小系统还很简陋,没有网络共享,因此最粗暴的方式就是挂载镜像——复制——启动系统。
1 | $ sudo mount -o loop ~/varm/os/rootfs.ext3 /mnt |
第三步:加载/卸载
记住linux最简单的管理内核命令:
- insmod,加载内核模块
- rmmod,卸载内核模块
正如下图所示,hello.ko和预期一样分别在加载和卸载模块时打印出了相应的内容。
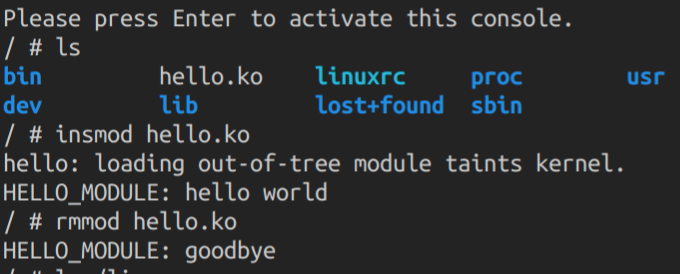
关于提示loading out-of-tree module taints kernel.主要是由于该模块并不存在设备树中,想想第一节的make dtbs,所以这个警告无关紧要。关键是第一个内核模块版本的HelloWorld顺利通过验收,鼓掌!
以上是本节的实操,结束!
以下是Linux内核知识,GO!
虚拟文件系统
对于Linux“玩家”而言,文件系统(File System)是非常简单的概念,比如Windows的NTFS、macOS的APFS、Linux的Ext4、U盘的Fat32等等,所以文件系统就是对物理存储空间的逻辑抽象和数据组织管理的机制,根据不同的操作系统或存储介质演化出了如今众多的文件系统类型,但不论如何,我们口中的文件系统泛指对存储介质的数据管理系统。而Linux更是将这种思想发挥到了极致——一切皆文件。
有了文件系统,我们可以非常直观地open、close、read、write任何文件,访问任何目录。但你有没有想过,硬盘里的“文件或目录”归根结底只是一些二进制数据,只要格式化就消失了。而计算机周围的键盘、鼠标、显示屏、打印机、摄像头等,这些可是真实设备啊,每种设备的操作方式都不同,意味着每增加一个设备,Linux内核就要专门为其开发一种API给用户访问,就算Linux社区的黑客们不嫌烦,我等芸芸众猿也学不过来呀。
为此,Linux社区孕育了“把每个设备抽象成一个文件”的想法,这样不论什么新设备都可以用open、close、read、write函数访问,而组织管理这些设备文件的,自然就是设备文件系统,比如/dev、/sys等目录,我暂且把它们称作设备文件系统。
此外,操作系统管理着很多进程,这些进程同样千奇百怪,如何让用户非常方便地访问呢?抽象成文件系统啊,每个进程都抽象成文件,直观地摆到用户面前,比如/proc目录,我暂且把它称作进程文件系统。
还有,我们的电脑是可以网络通信,通过http、ftp等,网络上的资源也是让人眼花缭乱,怎么能直观呢?浏览器是个不错的选择,但对于只有命令行的黑客呢?抽象成网络文件系统吧。
回首,掏再看看我们的根文件系统,最多把它称为硬盘文件系统。
所以那么多的文件系统摆在我的面前,Windows没有好好珍惜,只是甩给用户一堆ABCDEFG盘。Linux不想这样,它不希望用户觉察到文件系统的存在,让用户觉得“去他妈的文件系统,老子只是打开了一个文件夹”。所以为了解决不同文件系统的“共生”问题,虚拟文件系统诞生了!
重新认识dev、sys、proc目录
上边扯了一堆“废话”介绍有关虚拟文件系统的概念,换而言之,不要简单的认为/dev、/sys、/proc这几个根目录仅仅是个目录,否则接下来的设备驱动开发会看得云里雾里。
挂载proc文件系统
在介绍之前先启动之前用qemu做好的Linux系统,然后尝试用ps看一下进程😁
1 | ~/varm/os$ ./power_on.sh |
看,一个最简单的进程查看命令居然出错了,提示找不到/proc目录,简单啊——创建这个目录再试试:
1 | / # mkdir /proc |
错误提示不见了,但依然什么进程都没有,连系统进程都没有,这怎么可能,proc目录下空空如也…
呵呵,根本原因出在我们把/proc当作一个普通目录来处理了,正如前边所说,Linux会把所有的进程抽象为文件来组织管理,所以核心问题是以上命令并没有真正去挂载procfs,所以正确的做法是这样:
1 | / # mount -t proc proc /proc # 把proc文件系统挂载到/proc目录下 |
挂载sysfs文件系统
和proc文件系统道理一样,sysfs顾名但不要思义,顾名是指这个文件系统肯定是挂载到/sys目录,不要思义是指sysfs不是为了呈现系统而生的。
sysfs最开始Linux为了更好地以文件/目录形式在用户层展现设备树和驱动的结构及关联才开发的,其实就是从/proc/sys中剥离出来,所以最初其实这个文件系统名为ddfs(Device-Driver-FS)。后来这个文件系统和驱动模型被证明在其他子系统中也大有作为,就干脆叫做sysfs。
说那么多,要搞清楚,/sys这个目录主要是为了清晰呈现设备、驱动、类型之间的关联(如果你不嫌烦可以一个个子目录翻了看看,其中有很多符号链接)。今后写驱动,可能会频繁地访问该目录。
好了,把sysfs也挂载起来吧
1 | / # mkdir /sys |
/dev与udev
其实如果你不较真儿的话,/dev可以就是个目录,但常见的Linux版本中更喜欢把它挂载到tmpfs文件系统,说白了就是个虚拟硬盘,临时内存区而已。说它可以是个普通目录的意思,是说该目录下的所有文件,理论上来说都是在用户层完成的,非内核在管理。设备和驱动真正被内核管理的地方是刚说的sysfs。这也是为什么在很多嵌入式Linux文件系统的启动脚本里,会有各种mknod命令出现。
那/dev目录存在的意义是什么?很简单——设备描述符。任何设备被Linux抽象的符号链接最终都应该放在这里,比如我们要访问串口,不是区/sys目录下找XX设备,而是应该找/dev/ttyXXX设备描述符。
udev是什么?解释之前先了解另一个东东——devfs,这货其实就是最开始内核来管理设备的文件系统了,也就是说刚开始一个u盘插入后各种驱动加载、指定设备号、创建文件描述符等等工作都由它完成。出发点自然是很好,但封闭的弊端就是不灵活。此时udev注意到这些缺点,而且认为什么加载驱动、创建文件符号这些事情完全可以留给用户曾作,画蛇添足干嘛,所以udev才取代了devfs。
简单来说,udev也类似于文件系统管理着/dev目录,但运行在用户态,通过监听uevent,动态为插拔设备做各种驱动加载、创建文件描述符等,但这些行为是根据用户层的匹配规则完成的。
小结一下
- vscode和c/c++扩展可以很好地支持Linux驱动的代码编辑
- 内核模块编译依赖于内核源码,并通过
obj-m=xxx.o指定模块名称 insmod xxx.ko加载一个内核模块rmmod xxx卸载一个内核模块/dev /proc /sys目录其实是三个文件系统