二:从入门到放弃
⚠️警告⚠️
本书第二章不适合新手阅读!
本书第二章不适合新手阅读!
本书第二章不适合新手阅读!
如果说第一章读起来还算愉快,就像上高数课一样,刚开始老师告诉你,这是Σi是求和的符号,i从0到100,很好理解对吧,然后你走神一秒钟,黑板上写满了各种微积分公示和计算过程…what the fuck?!
本章涉及到的知识点较多且杂:
- RSS、XML和JSON语法规则
- GO语言的并发操作goroutine
- GO语言的数据同步
- GO语言类型、接口的定义与使用
- GO语言数组、切片的定义与使用
其实本章一开始就说了,没必要第一次就读懂本章所有内容,我想作者的本意应该只是让读者感受一下GO语言的整体和编程思想,让读者明白,自己对力量的一无所知。
本章相关的源码放在https://github.com/goinaction/code/tree/master/chapter2/sample,我读完本章并自我感觉理解之后自己“手抄”了一遍,大体和原著框架一致,细节上有所变动,基本上可以在当前文档执行go run main.go查看效果。
我的第一个RSS阅读器
本章其实就做了一件事,写一个自己的RSS阅读器,根据用户的rss订阅表和关键字输入,搜集网上所有含有关键字的“新闻”,并在终端打印出来。
用户的rss订阅表是由json写的,大概长这个样子:
1 | [ |
所以我们的RSS阅读器程序需要完成一下几个步骤:
- 读取并反序列化用户订阅表——data.json
- 为订阅表中的每个URL启动一个并发任务——新闻搜索
- 抓到之后,根据用户输入关键字,采用正则表达式过滤
- 将过滤结果打印至终端后,单个并发任务退出
- 启动一个并发任务,专门监听其他新闻搜索任务是否退出
- 等待所有新闻搜索任务退出后,程序退出
根据以上流程,书中对整个程序设计的架构图已经表达得比较清楚了: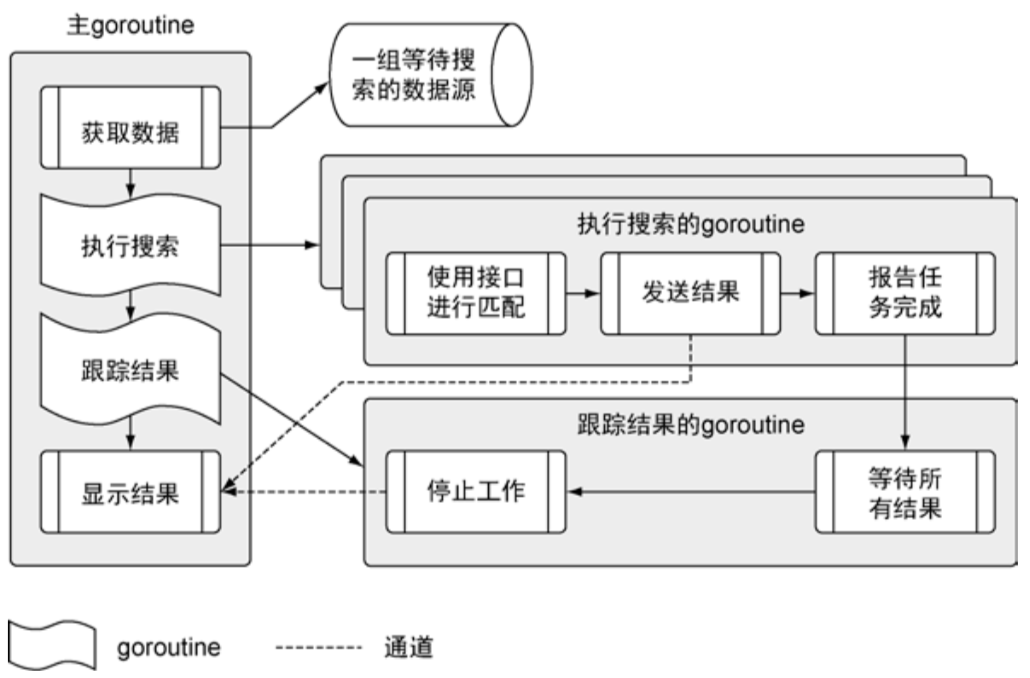
整个工程的目录结构:
1 | - sample |
1. 关于数据源data.json和feed.go
可以简单理解,feed.go就是data.json的ORM。
Feed是一个类型,根据订阅表的数据结构site/link/type来对应其内部的三个属性。RetrieveFeeds()仅负责加载data.json文件,并反序列化所有项目,装到Feed列表里。
搞清楚结构体的定义就行:
1 | type Feed struct { |
注意每个属性最后那个由反引号括起来的标签,这很重要,应为数据源是json格式,而GO语言的json.Decoder可以根据这个标签的内容标记对原始的json数据进行反序列化。
2. 关于match.go接口,以及rss.go和default.go的实现
这三个文件一定要结合起来看,否则就云里雾里了。
- match模块声明了
Matcher.Search()接口行为、结果的数据结构和统一输出结果。 - default/rss都是是
Search()接口的具体实现。
1 | // match.Matcher 定义搜索匹配接口行为 |
default.go里其实啥也没有,它的存在只是为了容错(或者说展示一下接口最简单的运用方式),如果再看看Feed.Type就会发现,它映射的data.json里的type是字符串rss,而主函数search.Run()里其实是根据类型来查找相关匹配器的,换而言之,如果type的值不是rss而是其他类型,程序很可能会类似C/C++语言,越界访问数组而出错。所以干脆把找不到的类型全部设置成default类型。
rss.go模块就是具体的Http、XML、RSS、正则匹配的实现了,这部分相对独立与整体框架,不必太拘泥于此。
注意一点
default和rss都有个init()函数,而且实现得也很像,正如上面说的,init函数就是负责把自己以同名的方式保存到search.matchers当中,确保其他模块能后通过字符串的形式找到它们,这是个search模块的私有变量。
1 | // 在main函数之前执行,将自己的匹配器类型注册到search模块 |
3. 关于search.go
是整个阅读器的业务逻辑实现,也就是架构图当中左半部分获取数据、执行搜索、跟踪结果、显示结果几大步骤的调用,它本身并不负责实现任何搜索和匹配相关的功能。
- 负责调用feed模块,获取订阅表(数据源),并保存到feeds的切片当中
- 为每一个feed常见一个
goroutine,具体业务由Matcher接口相关的实现去执行 - 创建一个统一的
goroutine,监听/等待所有feeds匹配业务执行结束
我认为search.Run()比较重要,关于Matcher接口、JSON/XML、http等其他模块的实现看不懂也没关系,书后面的相关章节会深入解析,而Run函数中关于goroutine的并发启动和chan数据通道这两个概念一定要搞清楚。
以最简单的主监听器waitGroup的并发启动为例:
1 | go func() { |
关键字go foo()负责启动一个goroutine,紧随其后是一个闭包(当然,也可以在其他地方先定义一个函数),在这里可以看到,GO语言启动一个“线程”有多么愉快!
4. 关于Display()函数及其调用过程
Display是非常值得拎出来说道说道的,仔细观察就会发现Display是在所有goroutine启动完之后,才仅仅被调用了一次!
而该函数的内部实现却非常简单,就是个for循环:
1 | func Run(keyword string) { |
按照一个正常猿类的思维模式,如果集合被遍历完之后,循环就会自动跳出,而且由于并发情况下,一开始的results里面其实啥也没有,应该直接退出。而事实上的执行过程是:一旦results被写入数据,for循环就会执行一次。
为什么?
注意results的类型chan *Result,在for-range一个通道的情况下,只要通道没有被关闭,该循环就会被阻塞,一旦通道内写入数据,循环就会被唤醒,直到通道被关闭,循环跳出。(这种机制太风骚了)
5. 关于main.go
主模块唯一值得留意的地方是import _ "./matchers",这是刻意也是必须这样写的:
- GO语言不允许导入一个包,却不使用它
- matchers里面的rss和default模块都有init函数,不导入就不会被执行,会导致程序出错
- 下划线’_’表示一个占位符,类似for循环的占位操作,就是告诉编译器,我确实需要导入这个包,但并不调用它,我只需要它自己执行init函数
小结一下
- 包
- 每个代码文件都必须属于一个包,原则上包名和目录名一致
- 不论函数还是变量,首字母大写的标识符相当于
public,否则相当于private
任何包内的**init()**函数,都会先于main函数执行,前提是包被导入了。
多返回值是GO语言的一大特性,GO的很多核心库都是
result, err两个返回值。根据“江湖规矩”,如果定义一个变量需要初始化为零值,采用
var name type声明,如果是定义变量且被赋值,则采用name := value的形式定义range关键字
- 可用于迭代
数组、字符串、切片、映射和通道 - 每次迭代都有两个返回值,第一个是索引,第二个是当前元素的副本。
- 下划线
'_'表示一个占位符,就是说,“虽然你给我了,但老子就是不要”的意思
defer关键字表示函数返回时才执行,可以在open一个文件后,立刻调用
defer close,但关闭这个动作会等到调用函数返回的时候才真的执行。(妈妈再也不用担心我的句柄,so easy)goroutine,使用
go foo()的形式来启动一个并发,foo也可以是一个闭包。channel,通过
chan关键字声明一个通道,当使用range循环来遍历一个通道时,只要通道不关闭,循环就是阻塞,直到通道内的数据有变化,当通道关闭后,循环退出。