四:数组、切片、映射
本章开始,进入GO语言的基本数据结构的学习。我认为无论如何还是要仔细读一遍第4-6章,和其他“胎教”类的教科书不一样,这几章内容并不是教你:int表示一种整数、汽车摩托车都是车类,轮子是一种属性,跑是一种方法、数组就是一种连续的空间。相反,以本章内容为例,单刀直入告诉你数组、切片、映射的内存结构,实现原理,以及一些高级用法,不论新手老手,读一读总能有所收获。
数组
GO语言的数组类型和绝大多数其他编程语言的思想是类似的,没有太多新东西,把基本用法掌握即可。
基本定义
1 | // 创建并初始化一个长度为3的数组 |
看上边的代码,其他都很好理解,但是a2 = [...]这种形式很怪异,道理很好理解,就是a2的长度取决于后边定义的元素个数,但为什么要多三个点呢?能不能写成这样nums := []int{1, 2, 3, 4, 5}?
答:不能🙅!!省略三个点后,nums就声明为切片了,切片可以理解为动态长度的数组,但内存结构和数组完全不同!不要图方便就彼此混淆。
元素访问
1 | a := [...]int{1, 2, 3, 4, 5} |
数组克隆
1 | a := [...]int{1, 2, 3, 4, 5} |
指针数组
1 | // 和数组复制类似,nums2复制了nums1的内容 |
多维数组
1 | // 1. 声明一个多维(4行2列)数组 |
函数中数组传参 👈 务必要留意这条!
数组有非常多的应用场景:内容缓存、请求/应答消息等,此类数据有可能体积较为庞大,比如默认给某个buffer开2M的空间,让它在不同的函数间传递,然而GO语言函数参数中,数组是以复制的形式传递的,这就会导致每次调用函数压栈的开销特别大,如果您在来几个递归…那后果就是灾难性的。
所以,日常开发中,如果数组长度非常大,且作为一个”输入输出”参数,最好不要直接定义为数组,而是定义为数组指针。
切片
切片是对数组的进一步抽象,以便于达到“动态”增长数组的效果。但不要简单的理解为就是在数组的连续内存尾巴后“追加”新的内存,那是不阔愣滴~
切片的内存结构
切片是一个很小的对象,如下图所示,它有3个字段:地址、长度、容量。
- 地址:很好理解——指向数组的首地址,真正存储切片数据的地方
- 长度:切片实际上能索引的元素个数
- 容量:切片允许增长的元素个数
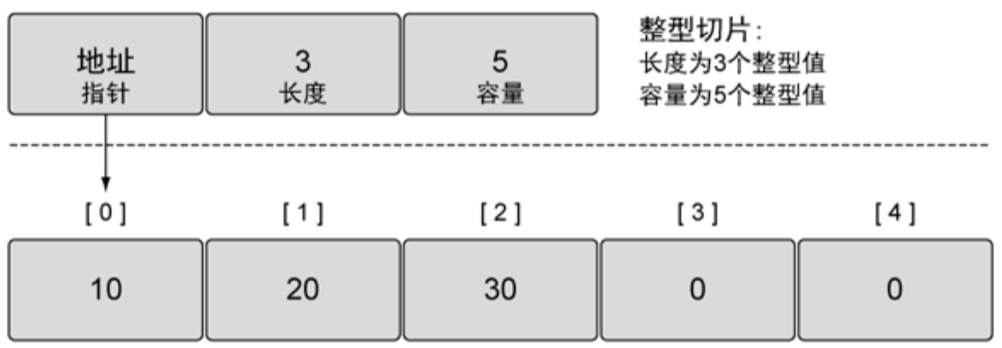
✍️划重点✍️
对我这种新手而言,容量和长度刚开始不太好理解,感觉就是一回事。其实不然,先记住一句话:长度和访问相关,容量和增长相关。
比如slice := make([]int, 3, 5),我们创建了一个长度为3,容量为5的切片:
- 如果我们试图访问第4个元素(即slice[3])时,就会报错,因为超出长度。
- 我们可以用append追加一个新元素——
newSlice := append(slice, 666),此时切片长度为4,但容量依旧为5。因为长度没有超过容量,不会分配新内存。 - 同理,我们在追加两个新元素,当长度超过了容量,容量就会直接翻倍,此时长度为6,容量为10。
👀向右看齐👀:切片容量小于1000是,每次都是成倍增长。超过1000时,每次增长25%,当然,这种增长算法可能会在未来作出改变。
1. 切片创建和初始化
1 | // 创建一个空切片 |
关于切片的元素访问,表面上就是个动态数组,所以它的使用和数组的形式几乎无二,这部分参考数组的内容即可。
2. 切片复制
切片复制和前边的数组复制大体上类似,使用方式上就不重复说明了。
关键是要弄懂切片内部的“数组地址”,从“切片的内存结构”可以了解,切片本身只有3个字段,其中第1个字段是数组的地址,所以复制一个切片后,修改副本的同时,原始切片的元素也会改变。
但是!!! ✍️你懂的✍️
依旧是长度和容量的问题,如果不把这里搞懂,一定会遇上各种诡异的事情!请看大屏幕代码:
1 | // 定义一个切片,长度和容量均为5 |
从上边的例子可以看出,当切片副本增长超出容量时,就会分配新内存空间,完全脱离原始切片。就会看到上面,时而访问的是同一个数组,时而访问的是两个不相干的数组。如果不把这里搞懂,在各种数据缓存、函数参数传递等情况下,无疑会留下巨大的坑。
3. 指定切片复制的容量
其实理解了切片对底层数组的内存管理(长度和容量),其实用dst := src[i:j]的拷贝方式也无妨,小心一点即可。
但GO语言提供了更健全的拷贝方式:dst := src[i:j:k]:
'i':表示要拷贝的原切片“地址”索引'j':表示要拷贝的原切片“长度”索引'k':表示要考呗的原切片“容量”索引
拷贝的时候限定新切片的容量是个不错的习惯,可能更好地管理内存空间,减少触发很多莫名其妙的情况。但要注意,指定的容量索引不可以超出原始切片的边界,否则就报错。
1 | // 以a[2]为起始地址,长度为3-2=1,容量为3-2=1,将切片复制给b |
多维切片、函数参数
多维切片同样可以理解为多维动态数组,例如二维切片的定义:
1 | // 定义一个二维 |
同时,切片本身只是个很小的对象,作为参数在函数间传递开销是很小的。就算我们定义了一个容量为100M的切片,但归根结底切片里存的仅仅是个数组的地址而已,根本不浪费栈空间。
映射(map)
映射就是一个存储键值对的无序集合。可以把它简单比作字典、哈希表之类的数据结构。
基本使用
map的使用是非常简单且灵活的,没什么需要特别注意的地方,此外作为函数参数进行传递时,并不会创造一个副本,在函数内部修改某个映射,外部也能察觉到修改。
1 | // 创建一个空的映射 |
内部实现
有关映射的内部实现书中讲的不多,也不是特别深入,可能因为背后的原理比较复杂,我只能把自己的理解大体做个总结,不一定准确!!
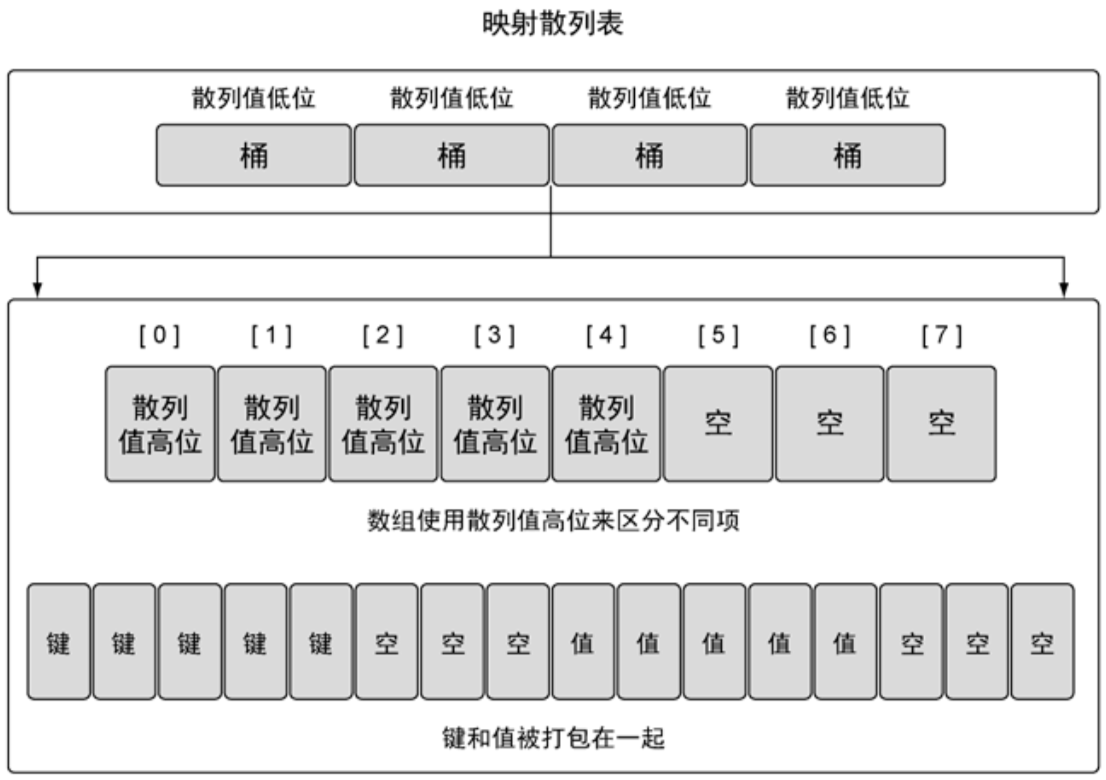
如上图所示,map的内部就是一堆桶和散列表:
- 桶:是多个键值对“打包”存放的一个连续的内存空间。
- 散列表:是根据某种散列算法,记录着不同的“键值”存储在哪个桶里。
简单来说,通过一个键可以计算出散列值——根据散列值找到对应的“桶”——从“桶”里把键所对应的那个值取出来。如下图所示:
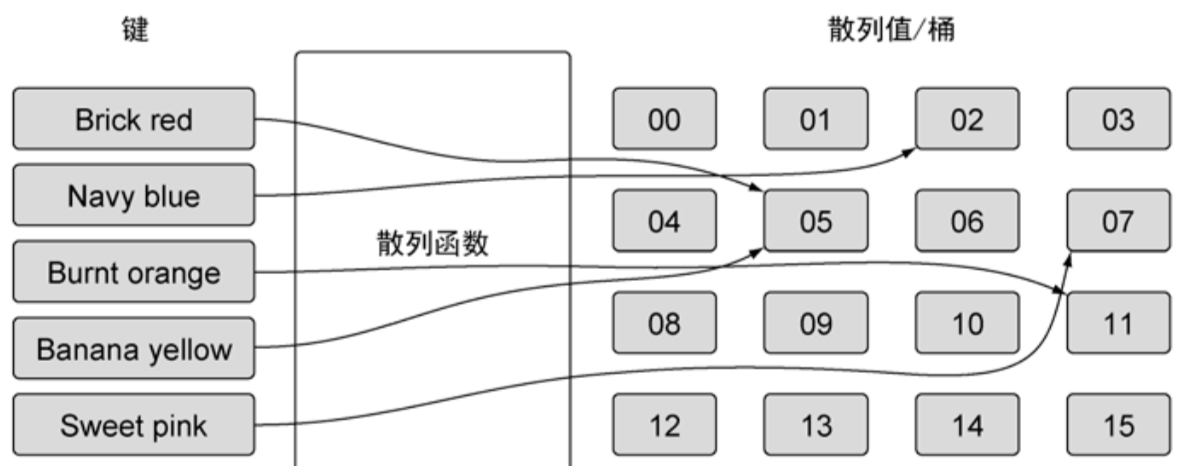
这个过程可能是非常复杂的,只需要记住:随着映射存储的增加,索引分布越均匀,访问值的速度就越快。
小结一下
- 数组是实现切片和映射的基石,后两者本质都是对数组的封装
- 切片为了“动态数组”,映射为了“数据字典”
- len函数用于返回数组、切片、映射的长度
- cap函数用于返回切片容量,且仅作用于切片
- make函数用于创建切片和映射,可以指定其长度(容量)
- append函数用于追加切片元素,且仅作用于切片
- delete函数用于删除映射元素,且仅作用于映射
- 作为函数参数传递时,数组的开销可能是巨大的,切片和映射不存在这个问题
- 切片追加元素,长度超过容量时,会重新分配内存,不再指向原来的