《自私的基因》读书笔记
我在很多书里看到对道金斯这本《自私的基因》的引用,感觉应该是一本奇书,最近终于有幸拜读一番,果然很精彩。正如道金斯自己所说,希望作者把它当作一本科幻小说来阅读,其内容涵盖哺乳动物、鸟类、昆虫等诸多“有趣”的行为或现象,以及大量的形象比喻,关于生命的生存与繁衍背后的“道理”讲得非常浅显易懂。
我在很多书里看到对道金斯这本《自私的基因》的引用,感觉应该是一本奇书,最近终于有幸拜读一番,果然很精彩。正如道金斯自己所说,希望作者把它当作一本科幻小说来阅读,其内容涵盖哺乳动物、鸟类、昆虫等诸多“有趣”的行为或现象,以及大量的形象比喻,关于生命的生存与繁衍背后的“道理”讲得非常浅显易懂。
类型——比“类”多了一个字而已,如果懂面向对象的话,类型的很多内容其实和面向对象语言如出一辙,但不同于面向对象思想。换而言之,Java/C#等常见的类的属性、方法、接口、继承等等形式,在GO的类型系统里都能找到身影,但其实现过程和思路却截然不同。
为了巩固本章的知识点,我仿照传统的MVC架构来实现一个“账户管理”的业务,作为GO与Java在实现面向对象方面的思想类比。在源码的account包中包含:
user——用户类型,基础模型admin——管理员类型,“继承”于usershow——视图,用户信息打印,用接口实现user和admin多态manage——服务,负责用户的增删改查在GO语言中定义一个类是非常简单的:type user struct {},当然,它不叫类,而是结构类型,很像C语言中的结构体。
在user.go里声明了两个类型:Password和User,高手一看便知Password其实就是内置的string类型,感觉两者是可以互换的。然而一旦做了这样的声明之后,GO的编译器就会吧Password和string严格当作两种独立的类型来处理。换句话说,不能把string定义的变量直接赋值给Password类型的对象,只能在初始化时接收纯字符串。
1 | type Password string |
此外,需要注意GO语言的符号可见性。以下情况适用于函数、变量、方法、属性等:
结构类型的使用也非常简单:
1 | // 定义并初始化一个结构 |
根据面向对象的套路,定义了类型的属性,自然少不了要定义方法,但GO语言不允许直接把一个类型的方法定义在其内部,而是可以将其定义在任何其他地方。如果习惯了Java这种方式,可能会觉得十分别扭,但这正是GO类型灵活的地方。如果你觉得某个“业务对象”需要某个特殊的方法来处理,那就直接加上好了,不影响它的继承、耦合等问题。
给类型添加一个方法的基本语法为:
1 | // u表示接收者,可以理解为面向对象中的一个对象 |
不过添加方法时需要注意“接受者”的区别,主要有两种:
值接收者的方法在其内部修改对象的值,不改变外部调用者指针接收者的方法在其内部修改对象的值,改变外部调用者还是以代码为例:
1 | // 值接受者方法 |
如果理解函数调用的内存管理,那这两种形式非常容易理解。调用函数的时候,传入的参数将拷贝一个副本并压栈,函数通过访问栈区来获取参数值。换句话说:所有传入函数的参数其实都只是副本,在函数内部修改副本的值,不会影响原始参数值。
✍️但务必注意✍️
Go语言里的引用类型:切片、映射、通道、接口和函数是比较特殊的,前几章已经说明了它们作为参数在函数间传递时,本身就是以引用形式传递,所以引用类型的方法,值接受者其实是个引用(指针)副本。千万小心。
User类型的属性和方法都实现了,在面向对象里面自然少不了继承,例如管理员账户Administrator类型一般而言都会继承User。GO语言对继承的形式如下:
1 | // Administrator 管理员用户 |
接口在第二章中其实总结了很多了,GO语言的接口属于鸭子类型——也就是一个类型只要实现了接口的方法,不管它们是否存在继承关系,都能够以多态的形式调用。
这里以Shower接口为例,该接口要求实现一个show方法,用于打印一个类型的内部信息。和面向对象的思路一样,各个类型实现自己的show方法,而Shower只负责调用。
首先是接口的定义:
1 | // Shower 显示接口的定义 |
下面是User和Administrator的不同show实现:
1 | // User类型实现show接口 |
从上边的例子可以看到,user和admin虽然是不同的类型,但是由于都实现了show这个接口方法,因此都可以传入ShowInfo函数,并且也实际调用到了它们各自的实现。
Don’t Just Learn the Language, Understand its Culture
在上大学的时候,我不得不去学习一门外语。当时我觉得自己的英语水平已经很牛逼了,就选择休学3年法语班。最近几年我去突尼斯度假。在那边阿拉伯语是官方语言,由于曾被法国殖民,法语也是比较通用的。语言则仅在旅游地区才讲。由于我对语言的无知,我发现自己只能在泳池边阅读Finnegans Wake(芬尼根的守灵夜),James Joyce的形式和语言之旅。尽管让人精疲力尽,但Joyce十分诙谐地融合了40多种语言真的十分惊人。认识到不同外语和语法的交织能够给作者带来新的自我表达方式后,这也成了我编程职业生涯中一直保持的事。
在他们开创性的书《程序员修炼之道》中,Andy Hunt和Dave Thomas鼓励我们每年都学一门新语言。我已经尝试过他们的建议,并在多年来有多种语言的编程经验。(以下是)我从各种语言冒险学到的,相比于只学习语言语法而言要重要得多:你要理解它背后的文化。你可以在任何语言中用Fortran,但只有真的学会一门语言你才会拥抱它。如果你的C#代码是一个很长的由众多静态Helper方法组成的Main方法,不要找借口,去了解类的本质。别总是羞于在函数式语言中花很长时间去了解正则表达式,强迫自己使用它们。
当你上手一次新语言,你会惊讶地发现你居然会以全新的方式使用你已经掌握的语言。我从Ruby编程中学会了如何高效地在C#中使用委托,完全释放.Net泛型的潜力给了我如何让Java泛型跟有用的灵感,LINQ让我自学Scala时更轻松。
你也可以从不同语言中更好地理解设计模式。C程序员会发现C#和Java已经将迭代器模式封装好了。在Ruby以及其他动态语言中你可能仍然采用访问者(模式),但你的实现却不会像GoF书中的例子那样。
有些争论认为《芬尼根的守灵夜》根本不可读,但也有人赞叹它的文风优美。为了减少对本书的阅读恐惧,单一语言的翻译版本也许可行。讽刺的是(度假的地方)法语才是第一语言。代码在很多地方是相似的。如果你写的守灵夜代码采用一点点Python、一些些Java和一丝丝Erlang,你的工程将混乱不堪。但如果你通过新语言大开脑洞获得灵感,能用不同的方式来解决事情,你会发现在写代码时旧语言可以为你学到的任何新语言带来更多美好。
首先,电影拍的实在太赞了!!
其次,小说的想象力太丰富了!!
关于电影,不论是画面、剧情还是节奏感,统统把我俘获了,唯一后悔的就是没有选择IMAX。我特别欣赏影片的视角(或者说价值观),真正的英雄是所有齐心协力的人类,并非美国大片中的个别英雄。但我不喜欢网上一味拿“民族自豪感”和“好莱坞级科幻片”相提并论,给我的感觉就是在自嗨氏的刷存在感,中国电影有自己的魅力,不要总拿西方的标准来衡量。另外,我也真是服了那些喷子,吹毛求疵地去挑内容的不科学性,这就是部科幻片,就和刘谦的魔术一样,本来就是艺术。非要卖弄一下自己的学问来“证明”它不合理,你行你上啊!
关于小说,主要是看完电影忍不住想要了解原著,中篇小说,一口气就读完了。小说的剧情和电影差别太大了,或者干脆说,电影只是汲取了小说的故事背景和几个基本剧情,以及刘慈欣的想象力元素。要我说,小说里“叛乱”、“穿越小行星带”、“氦闪”等情节都非常适合拍成电影(要是能有第二部就好了😊)。
一天傍晚我走在一条街道上准备去酒吧见几个朋友。我们已经有段时间没一起和啤酒了,我很期待再见到他们。仓忙之中,我没有看路。我被路边缘给绊倒了,脸贴地。好吧,我猜这是对我粗心大意的正确处置。
腿受伤了,但我急着见我的朋友。因此爬起来继续。走没多远远疼痛加剧。尽管刚开始我想这只是阵痛,很快我就意识到错了。
但我没理会,抓紧去酒吧。终于到了,痛苦万分。我并没有度过一个愉快的夜晚,因为总觉得很疼。第二天一早我就去看医生,发现我胫骨骨折了。当时觉得疼的时候就停下来,我就能防止因为走路造成的更大伤害。那可能是我生命中最糟糕的一个早上了。
很多程序员写代码就像我那个悲催的夜晚。
错误,什么错误?又不严重。老实说,我能忽略它。这可不是一个能巩固代码的策略。事实上,这只是纯粹的懒惰。(错误的排序)不管你多不喜欢思考你代码中的错误,你都应该检查它,并总是把它处理掉。任何时候。如果你不这么做,就无法节省时间:你只是在给未来积攒潜在的问题而已。
我们报告代码中的错误有很多种方式,包括:
printf的返回值?1 | try { |
这种可怕的结构的优点在于它强调了你所做的道德上的可疑事实(译注:我不明白try-catch和道德有什么关系🤔️)
如果你忽略错误、视而不见、假装没有什么事情出错,你在酝酿一个大风险。正如我的腿最终处于一个很糟糕的状态,是因为我没有立刻停止走动,毫无责任心的耕耘总会酿成大祸。在最早有条件的时候把问题处理掉。轻装上阵。
不处理错误将导致:
就像你应该检查代码中所有潜在的错误一样,你需要揭露接口中所有潜在的错误情况。不要隐藏他们,假装你的服务总可以工作。
为什么我们不检查错误?有很多常见的借口。你会同意哪一个?又会如何反对每一个?
我之前从未听过瑞达里奥以及他的桥水公司,直到我读了这本书,才发现原来是个牛逼闪闪的人物。但不管他的光环有多么耀眼,“被推荐”——才是我买这本书的唯一理由,需要坦言,这本书并不适合我,原因有二:
本章开始,进入GO语言的基本数据结构的学习。我认为无论如何还是要仔细读一遍第4-6章,和其他“胎教”类的教科书不一样,这几章内容并不是教你:int表示一种整数、汽车摩托车都是车类,轮子是一种属性,跑是一种方法、数组就是一种连续的空间。相反,以本章内容为例,单刀直入告诉你数组、切片、映射的内存结构,实现原理,以及一些高级用法,不论新手老手,读一读总能有所收获。
GO语言的数组类型和绝大多数其他编程语言的思想是类似的,没有太多新东西,把基本用法掌握即可。
1 | // 创建并初始化一个长度为3的数组 |
看上边的代码,其他都很好理解,但是a2 = [...]这种形式很怪异,道理很好理解,就是a2的长度取决于后边定义的元素个数,但为什么要多三个点呢?能不能写成这样nums := []int{1, 2, 3, 4, 5}?
答:不能🙅!!省略三个点后,nums就声明为切片了,切片可以理解为动态长度的数组,但内存结构和数组完全不同!不要图方便就彼此混淆。
1 | a := [...]int{1, 2, 3, 4, 5} |
1 | a := [...]int{1, 2, 3, 4, 5} |
1 | // 和数组复制类似,nums2复制了nums1的内容 |
1 | // 1. 声明一个多维(4行2列)数组 |
数组有非常多的应用场景:内容缓存、请求/应答消息等,此类数据有可能体积较为庞大,比如默认给某个buffer开2M的空间,让它在不同的函数间传递,然而GO语言函数参数中,数组是以复制的形式传递的,这就会导致每次调用函数压栈的开销特别大,如果您在来几个递归…那后果就是灾难性的。
所以,日常开发中,如果数组长度非常大,且作为一个”输入输出”参数,最好不要直接定义为数组,而是定义为数组指针。
切片是对数组的进一步抽象,以便于达到“动态”增长数组的效果。但不要简单的理解为就是在数组的连续内存尾巴后“追加”新的内存,那是不阔愣滴~
切片是一个很小的对象,如下图所示,它有3个字段:地址、长度、容量。
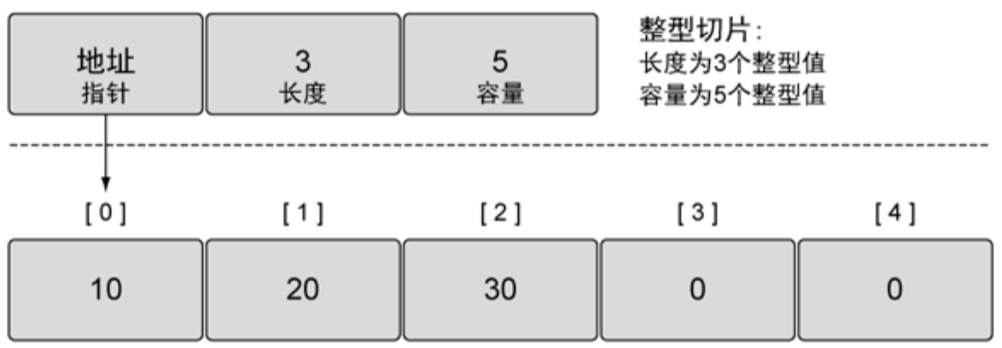
✍️划重点✍️
对我这种新手而言,容量和长度刚开始不太好理解,感觉就是一回事。其实不然,先记住一句话:长度和访问相关,容量和增长相关。
比如slice := make([]int, 3, 5),我们创建了一个长度为3,容量为5的切片:
newSlice := append(slice, 666),此时切片长度为4,但容量依旧为5。因为长度没有超过容量,不会分配新内存。👀向右看齐👀:切片容量小于1000是,每次都是成倍增长。超过1000时,每次增长25%,当然,这种增长算法可能会在未来作出改变。
1 | // 创建一个空切片 |
关于切片的元素访问,表面上就是个动态数组,所以它的使用和数组的形式几乎无二,这部分参考数组的内容即可。
切片复制和前边的数组复制大体上类似,使用方式上就不重复说明了。
关键是要弄懂切片内部的“数组地址”,从“切片的内存结构”可以了解,切片本身只有3个字段,其中第1个字段是数组的地址,所以复制一个切片后,修改副本的同时,原始切片的元素也会改变。
但是!!! ✍️你懂的✍️
依旧是长度和容量的问题,如果不把这里搞懂,一定会遇上各种诡异的事情!请看大屏幕代码:
1 | // 定义一个切片,长度和容量均为5 |
从上边的例子可以看出,当切片副本增长超出容量时,就会分配新内存空间,完全脱离原始切片。就会看到上面,时而访问的是同一个数组,时而访问的是两个不相干的数组。如果不把这里搞懂,在各种数据缓存、函数参数传递等情况下,无疑会留下巨大的坑。
其实理解了切片对底层数组的内存管理(长度和容量),其实用dst := src[i:j]的拷贝方式也无妨,小心一点即可。
但GO语言提供了更健全的拷贝方式:dst := src[i:j:k]:
'i':表示要拷贝的原切片“地址”索引'j':表示要拷贝的原切片“长度”索引'k':表示要考呗的原切片“容量”索引拷贝的时候限定新切片的容量是个不错的习惯,可能更好地管理内存空间,减少触发很多莫名其妙的情况。但要注意,指定的容量索引不可以超出原始切片的边界,否则就报错。
1 | // 以a[2]为起始地址,长度为3-2=1,容量为3-2=1,将切片复制给b |
多维切片同样可以理解为多维动态数组,例如二维切片的定义:
1 | // 定义一个二维 |
同时,切片本身只是个很小的对象,作为参数在函数间传递开销是很小的。就算我们定义了一个容量为100M的切片,但归根结底切片里存的仅仅是个数组的地址而已,根本不浪费栈空间。
映射就是一个存储键值对的无序集合。可以把它简单比作字典、哈希表之类的数据结构。
map的使用是非常简单且灵活的,没什么需要特别注意的地方,此外作为函数参数进行传递时,并不会创造一个副本,在函数内部修改某个映射,外部也能察觉到修改。
1 | // 创建一个空的映射 |
有关映射的内部实现书中讲的不多,也不是特别深入,可能因为背后的原理比较复杂,我只能把自己的理解大体做个总结,不一定准确!!
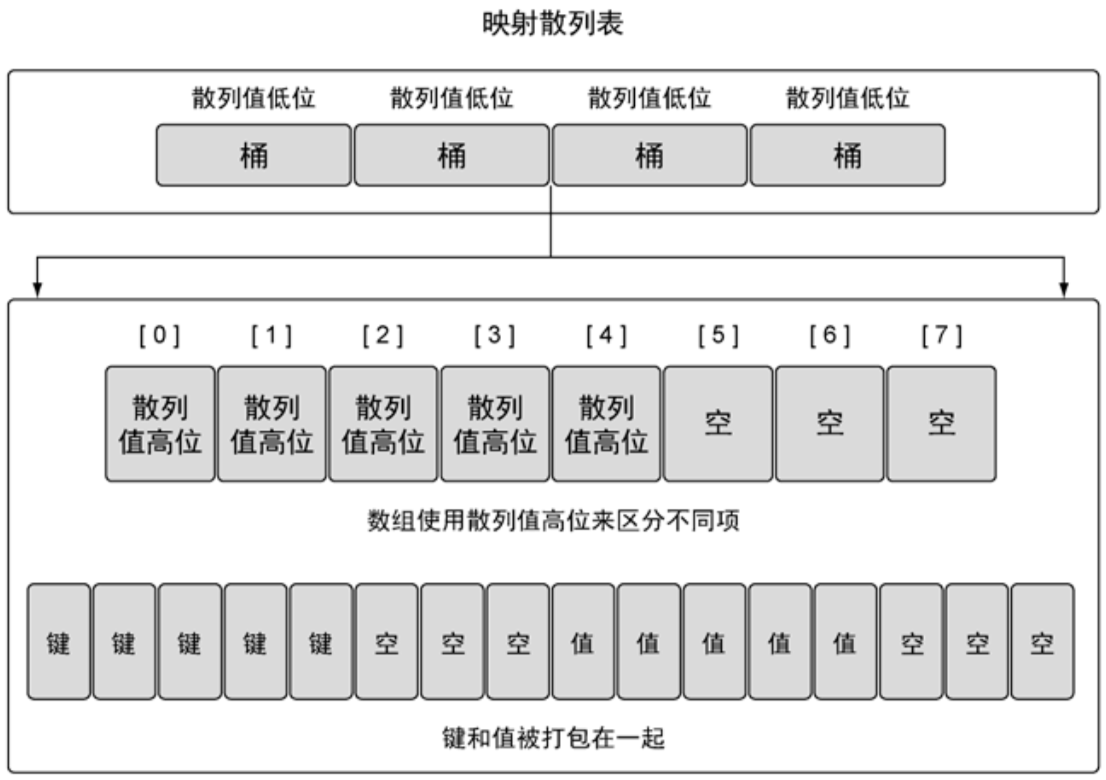
如上图所示,map的内部就是一堆桶和散列表:
简单来说,通过一个键可以计算出散列值——根据散列值找到对应的“桶”——从“桶”里把键所对应的那个值取出来。如下图所示:
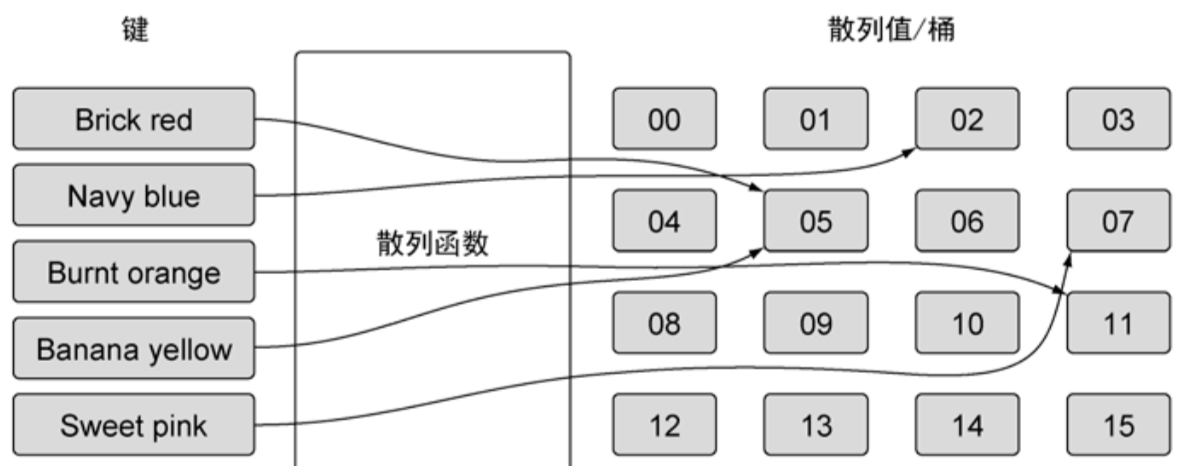
这个过程可能是非常复杂的,只需要记住:随着映射存储的增加,索引分布越均匀,访问值的速度就越快。
Don’t Be Cute with Your Test Data
已经晚了。我已经抛出一些占位符数据来测试我做的页面排版。
我用The Clash(冲撞乐队)作为用户名。公司名?Sex Pistols(性手枪)的歌曲名可以充当。现在我还需要一些股票代码——仅仅需要4个大些字母即可。
我用了上面四个单词的首字母。
它们看上去是无害的。仅仅是我的自娱自乐,或许第二天就会有开发者在我之前改为真实数据。
结果第二天一早,一个项目经理截取了一些屏幕快照作为演示。
编程历史充斥着这些战争故事。开发者和设计师做所的“没有人会看到”的事情突然意外变得可见。泄漏的类型各不相同,当发生时,它对负责的个人、团队、或公司都是致命的。例如下面这些:
印证了那句老话“谣言走遍天下,真理寸步难行”,在今天这个时代,在开发者的时区,任何人醒来之前,都会出来Dugg、Twittered和Flibflarbed(译注:这三个单词我不懂😫)。
既是你的代码并非没有审查。在2004年,当Windows2000的源码包被共享到网上时,有些人乐此不疲地拿它来亵渎、侮辱和恶搞。(我承认,注释// TERRIBLE HORRIBLE NO GOOD VERY BAD HACK,也不时被我引用——译注:这条注释源自Windows泄露源码里)
总的来说,当你写任何文本到代码里时——无论注释、日志、对话框、或者测试数据——总要问问自己,如果它被公开看到将会怎样。它将全面让人脸红。
Don’t Be Afraid to Break Things
有过从业经验的人都毫无疑问在一个代码库不稳定的项目上工作过。该系统很烂,而且改变任何一件事总要涉及破坏其他无关的特性。不论什么时候添加一个模块,程序员的目标都是尽可能做很小的改变,每次发布时他们都屏住呼吸。这种软件就相当于在摩天大楼里玩I珠型Jenga(堆堆乐),总会招致灾难。
年久失修的原因是由于系统本身太恶心了。它需要一个医生,否则只会更糟糕。你已经知道你的系统出错了,但你惧怕打破鸡蛋来做成荷包蛋。一个有经验的外科医生知道必须要切割是为了进一步手术,但他也知道切割是短暂的并且会很快愈合。初期的疼痛对于手术的最终结果是有价值的,而且病人会很快恢复致比他们做外科手术前还要好的状态。
不要害怕你的代码。谁会在乎你搬东西的时候把某样东西暂时打破了?对改变的惧怕而陷入瘫痪是你的项目从一开始就维持这种状态的原因。投入时间去重构将会在整个项目周期内多次收回(时间)成本。同时受益的是你的团队更有经验去处理这个原本糟糕的系统,是你们所有专家都能了解它是如何工作的。接受这些知识而不是憎恨它。在一个你讨厌的系统上工作可不是每个人都应该浪费的必要时间啊。
重定义内部接口、重构模块、重构“复制粘贴”的代码、以及通过减少依赖来简化你的设计。通过消除极端情况你可以显著降低代码复杂性,这些基本是由不正确的功能连接导致的。慢慢地将旧的结构过渡到新的,并顺着(过渡)这条路测试。试图去“一波流”完成一个庞大的重构,会招致足够多的问题促使你想要半途放弃所有的努力。
作为外科医生是不会害怕切除病变的部分的,要为愈合腾出空间。这种态度具有感染力,会鼓舞其他人开始处理那些他们之前没有清理的项目。为了项目的良好生产,保持一个让团队觉得有价值的“卫生”的任务列表。说服管理层,哪怕这些任务可能无法产生可见的结果,但他们可以降低成本加速发布。永远停止关注生产“健康”的代码。
结束了上一章地狱般的折麽,从本章开始便重新回归胎教级别,如果说第二章的内容已经完全掌握,我觉得剩下的第3~5章基本可以略过了。
如果连“包”的基本概念都不了解,那就先别往下看了,去学学Java的基础知识吧。本书没有过多概念性的解释,而是具体说明在GO语言中,如何定义和使用包。
包名应全部小写,每个.go文件都必须在第一行使用package <name>声明自己属于哪个包,同一个目录下不同的go源码必须声明为同一个包。此外,不同路径下的包名是可以相同的,因为导入包时采用的是全路径,路径本身可以区分不同的包。
另外,main包很特殊,如果一个工程内编译器没有找到main包,就不会创建可执行文件,main()函数也必须在main包中定义。
导入方式
go语言支持远程导入、本地导入和命名导入:
import "fmt"import “github.com/spf13/viper” import myFmt "fmt"本地/远程导入,都是为了能愉快地使用别人已经写好的功能,不必重新发明轮子。而命名导入主要是为了方式重名包,例如:
1 | // 两个buffer包名相同,存在冲突,调用时有歧义 |
此外,不管用哪种方式导入,编译器都会先从GO的安装路径$GOROOT中寻找,没有的话就是$GOPATH中查找。
⚠️注意:
本地导入和远程导入从本质上讲没有区别。远程导入就是先从网上把第三方库下载到GOPATH当中,当作本地库import。
GOROOT和GOPATH
一个C/C++程序员(我是说我)比较容易犯的一个概念性错误——通过相对路径导入。举个例子:
如果某个工程源码结构是这样的:
1 | project/ |
在上边👆的目录结构可以看到,packages目录和main.go文件在同一级目录下,如果习惯了C/C++的思想,会这样导入packages下面的包:
1 | import ( |
从相对路径的角度来看,这么干没问题,但我们忽略了GOROOT/GOPATH两个环境变量,GO语言只会从根据这两个环境变量去寻找包。
GOROOT通常是go语言安装路径,比如/usr/local/go/GOPATH通常是用户自定义包路径这种套路非常类似于Java项目开发中的JAVA_HOME、CLASSPATH的概念。
需要注意一点,go编译器会自动为这两个环境后追加src目录,也就是说工程依赖的包应该放在$GOPATH/src内。换而言之,上边的packages目录必须放置在project/src内,并将工程目录添加到GOPATH中。
如果是远程导入,可以使用go get命令,下来源码中声明的“远程包”,它还会自动下载和更新各种依赖,但由于防火<哔哔>的缘故,这个命令大概率会timeout,只能曲线救国…
说明一下原因,当使用go get -v自动下载依赖包的时候,就可以看到整个过程,会默认去访问https://golang.org/x/<pkg>更新这些依赖,而golang.org的背后是一家名叫Google的公司在运营,由于我个遵纪守法的好公民,在我心目中只要我听不到看不到,它就不存在,是的,从小就在书本里学到一个成语——掩耳盗铃。
所以,我很奇怪,为什么go命令行要去访问一个根本不存在的网站,可能是个bug。好在机智如我,GitHub的GO仓库其实本质上就是golang.org/x 的镜像,所以务必记住这个镜像地址:
1 | ✍️划重点✍️ |
之前已经学习到,每个包内的init函数总是先于main函数执行,但前提是这个包在程序中被导入了。
很多时候,我们需要执行包内的init()函数来初始化某些资源,但我们不会去直接调用包内的任何变量。由于GO的限制,不允许导入一个根本不曾使用的包。
那么问题来了,如何导入一个包,却表面上不使用它?import _ <package_name>是个不错的选择。
对于我们这些Linux出身的猿类来说,敲命令来管理工程是非常有吸引力的,因为可以了解并掌握更多细节,自由度更高。
不论官方还是社区,go语言提供了非常丰富的命令,书中列举不是很多,我也觉得这种东西更适合直接看手册,我在此仅总结几个新手常用的,便于巩固记忆。
go build构建工程go clean清理工程go run <file.go>运行工程源码,其实是后台自动帮你完成构建go doc <key>命令行文档查看器,包、函数、符号等具体使用规则作为go新手,我可能还没体验过大型项目那种复杂的依赖关系,但作为nodejs、java的实践者,我很清楚依赖管理的好处。不论是npm还是maven,它们对效率的提升是巨大的。
gb源自社区,目的是解决go的第三方依赖问题。试想一下,对于一个大型项目,几十上百个第三方库,不同的版本,库与库之间的藕断丝连,一个个去筛查定位,无疑是在浪费生命。
gb其实就是在工程目录下,创建一个vendor目录,里面存放各种需要的依赖库,gb会自动下载、更新这些库文件,不用开发者操心(总之用过npm/maven的人都懂,懒得解释了)。
自己的工程目录就放在src目录下,不会和第三方的依赖有刮扯,需要构建工程的时候,仅需gb build all,搞定!